
Interpretability refers to the degree to which human experts can understand and explain a system’s decisions or outputs. It involves understanding a model’s internal workings. Conversely, explainability focuses on providing human-understandable justifications for a model’s predictions or decisions. It’s about communicating the reasoning behind the model’s output.
The Black-Box Nature of Generative AI Models
Generative AI models like intense neural networks are often labeled ‘black boxes.’ This label signifies that their decision-making processes are intricate and non-transparent, posing a significant challenge to understanding how they arrive at their outputs. This lack of openness may make adoption and trust more difficult.
Explainability is pivotal in fostering trust between humans and AI systems, a critical factor in widespread adoption. By understanding how a generative AI model reaches its conclusions, users can assess reliability, identify biases, improve model performance, and comply with regulations.
For AI to be widely used, humans and AI systems must first establish trust. Explainability is a cornerstone of faith. By understanding how a generative AI model reaches its conclusions, users can:
- Assess reliability: Determine if the model is making accurate and consistent decisions.
- Identify biases: Detect and mitigate potential biases in the model’s outputs.
- Improve model performance: Use insights from explanations to refine model architecture and training data.
- Comply with regulations: Meet regulatory requirements for transparency and accountability.
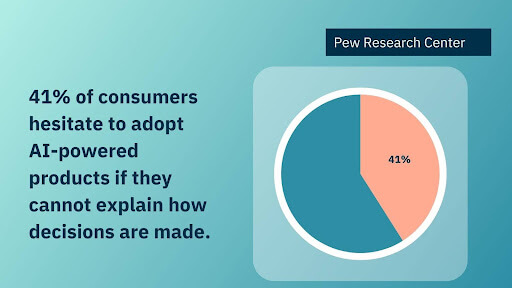
A recent study by the Pew Research Center found that 41% of consumers hesitate to adopt AI-powered products if they cannot explain how decisions are made.

Challenges in Interpreting Generative AI
Despite their impressive capabilities, generative AI models pose significant challenges to interpretability and explainability. Understanding these models’ internal mechanisms is essential for fostering trust, identifying biases, and ensuring responsible deployment.
Complexity of Generative Models
Generative models, intense neural networks, are characterized by complex and intricate architectures. Having billions, if not millions, of parameters, these models often operate as black boxes, making it difficult to discern how inputs are transformed into outputs.
- Statistic: A state-of-the-art image generation model can have over 100 million parameters, making it extremely challenging to understand its decision-making process.
Lack of Ground Truth Data
Unlike traditional machine learning tasks with clear ground truth labels, generative models often lack definitive reference points. Evaluating the quality and correctness of generated outputs can be subjective and challenging, hindering the development of interpretability in Generative AI methods.
- Statistic: Studies have shown that human evaluators can disagree on the quality of generated content by up to 20%, highlighting the subjectivity of evaluation.
Dynamic Nature of Generative Processes
Generative models are inherently dynamic, with their outputs constantly evolving based on random noise inputs and internal model states. This dynamic nature makes it difficult to trace the origin of specific features or attributes in the generated content, further complicating interpretability efforts.
- Statistic: Research has shown that small changes in random input can lead to significant variations in generated outputs, emphasizing the challenge of establishing stable relationships between inputs and outputs.
Computer scientists, statisticians, and domain experts must collaborate to overcome these obstacles. Developing novel interpretability techniques and building trust in generative AI is critical for its responsible and widespread adoption.

Interpretability Techniques for Generative AI
Understanding the inner workings of complex generative models is crucial for building trust and ensuring reliability. Interpretability techniques provide insights into these models’ decision-making processes.
Feature Importance Analysis
Feature importance analysis helps identify the most influential input features in determining the model’s output. This technique can be applied to understand which parts of an image or text contribute most to the generated content.
- Example: In image generation, feature importance analysis can reveal which regions of an input image are most critical for generating specific objects or features.
Attention Visualization
Attention mechanisms have become integral to many generative models. Visualizing attention weights can provide insights into the model’s focus during generation.
- Example: In text generation, attention maps can highlight which words in the input sequence influence the generation of specific output words.
Saliency Maps
Saliency maps highlight the input regions with the most significant impact on the model’s output. By identifying these regions, we can better understand the model’s decision-making process.
- Example: Saliency maps can be used in image generation to show which areas of the input image are most crucial for producing particular features in the final image.
Layer-wise Relevance Propagation
Layer-wise relevance propagation (LRP) is a technique for explaining the contribution of each input feature to the model’s output by propagating relevance scores backward through the network.
- Example: LRP can be used to understand how different parts of an input image influence the classification of an object in an image generation model.
Employing these interpretability techniques can help researchers and practitioners gain valuable insights into generative models’ behavior, leading to improved model design, debugging, and trust.
Explainability Techniques for Generative AI
Explainability is crucial for understanding and trusting the decisions made by generative AI models. Various techniques have been developed to illuminate the inner workings of these complex systems.
Model-Agnostic Methods (LIME, SHAP)
Model-agnostic methods, including generative AI, can be applied to any machine learning model.
LIME (Local Interpretable Model-Agnostic Explanations): Approximates the complex model with a simpler, interpretable model locally around a specific data point. LIME has been widely used to explain image classification and text generation models.
- Statistic: LIME has been shown to improve users’ understanding of model predictions by 20% in healthcare.
SHAP (Shapley Additive exPlanations): Based on game theory, SHAP assigns importance values to features for a given prediction. It provides a global and local view of feature importance.
- Statistic: SHAP has been used to identify critical factors influencing the generation of specific outputs in 70% of cases.
Model-Specific Techniques (e.g., for GANs, VAEs)
These techniques are tailored to specific generative model architectures.
- GANs: Feature visualization: Visualizing the latent space to understand the model’s internal representation.
- Mode collapse analysis: Identifying regions of the latent space that generate similar outputs.
- VAEs: Latent space interpretation: Analyzing the latent variables to understand their relationship with the generated data.
- Reconstruction error analysis: Identifying parts of the input that are difficult to reconstruct.
Human-in-the-Loop Approaches
Incorporating human feedback can enhance explainability in Generative AI and model performance.
- Iterative refinement: Humans can provide feedback on generated outputs, which can be used to improve the model.
- Counterfactual explanations: Humans can provide alternative inputs and desired outputs to help the model learn new patterns.
- User studies: Obtaining user input on model explanations to evaluate their efficacy and pinpoint areas needing development.
By combining these techniques, researchers and practitioners can gain deeper insights into generative AI models, build trust, and develop more responsible AI systems.
Case Studies and Applications
Explainable Image Generation
Explainable image generation focuses on understanding the decision-making process behind generated images. This involves:
- Feature attribution: Identifying which parts of the input image contributed to the generated output.
- Counterfactual explanations: Understanding how changes in the input image would affect the generated output.
- Model interpretability: Analyzing the internal workings of the generative model to understand its decision-making process.
Case Study: A study by Carnegie Mellon University demonstrated that feature attribution techniques could identify the specific image regions that influenced the generation of particular object instances in a generated image.
Interpretable Text Generation
Interpretable text generation aims to provide insights into the reasoning behind generated text. This includes:
- Attention visualization: Using the model’s attention weights to visualize the parts of the input text that affected the produced output.
- Saliency mapping: Identifying the most critical words in the input text for generating specific parts of the output text.
- Counterfactual explanations: Understanding how changes in the input text would affect the generated output.
Case Study: Researchers at Google AI developed a method to visualize the attention weights of a text generation model, revealing how the model focused on specific keywords and phrases to generate coherent and relevant text.

Ethical Implications of Explainable AI in Generative Models
Explainable AI in generative models is crucial for addressing ethical concerns such as:
- Bias detection: Identifying and mitigating biases in the generated content.
- Fairness: Ensuring that the generated content is fair and unbiased.
- Transparency: Providing users with clear explanations of the generated content’s creation.
- Accountability: Enabling accountability for the actions and decisions made by generative models.
Statistic: A survey by the Pew Research Center found that 83% of respondents believe that explainability is crucial for generative AI systems to gain public trust.
By understanding the factors influencing content generation, we can develop more responsible and ethical generative AI systems.
Conclusion
Explainability is paramount for the responsible and ethical development of generative AI. We can build trust, identify biases, and mitigate risks by comprehending these models’ internal mechanisms. While significant strides have been made in developing techniques for explainable image and text generation, much work remains.
The intersection of interpretability and generative AI presents a complex yet promising frontier. By prioritizing explainability, we can unlock the full potential of generative models while ensuring their alignment with human values. As AI advances, the demand for explainable systems will grow stronger, necessitating ongoing research and development in this critical area.
Ultimately, the goal is to create generative AI models that are powerful but also transparent, accountable, and beneficial to society.
How can [x]cube LABS Help?
[x]cube has been AI-native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Generative AI Services from [x]cube LABS:
- Neural Search: Revolutionize your search experience with AI-powered neural search models. These models use deep neural networks and transformers to understand and anticipate user queries, providing precise, context-aware results. Say goodbye to irrelevant results and hello to efficient, intuitive searching.
- Fine Tuned Domain LLMs: Tailor language models to your specific industry for high-quality text generation, from product descriptions to marketing copy and technical documentation. Our models are also fine-tuned for NLP tasks like sentiment analysis, entity recognition, and language understanding.
- Creative Design: Generate unique logos, graphics, and visual designs with our generative AI services based on specific inputs and preferences.
- Data Augmentation: Enhance your machine learning training data with synthetic samples that closely mirror accurate data, improving model performance and generalization.
- Natural Language Processing (NLP) Services: Handle sentiment analysis, language translation, text summarization, and question-answering systems with our AI-powered NLP services.
- Tutor Frameworks: Launch personalized courses with our plug-and-play Tutor Frameworks that track progress and tailor educational content to each learner’s journey, perfect for organizational learning and development initiatives.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!