
Information is significant in the quickly developing universe of AI (ML) and artificial reasoning (artificial intelligence). Notwithstanding, crude information is seldom excellent. It frequently contains missing qualities, clamor, or irregularities that can adversely affect the exhibition of AI models. This is where data preprocessing becomes an integral factor.
What is data preprocessing? ML calculations can utilize this fundamental stage of changing crude information into a perfect and organized design. Research suggests that 80% of data scientists‘ time is spent on data cleaning and preparation before model training (Forbes, 2016), highlighting its importance in the machine learning pipeline.
This blog will explore the key steps, importance, and techniques of data preprocessing in machine learning and provide insights into best practices and real-world applications.
What is Data Preprocessing?
Data preprocessing is a fundamental cycle in data science and a fake mental ability that unites cleaning, changing, and figuring out cruel data into a usable arrangement. This ensures that ML models can separate fundamental bits of information and make exact speculations.
The significance of information preprocessing lies in its capacity to:
- Remove inconsistencies and missing values.
- Normalize and scale data for better model performance.
- Reduce noise and enhance feature engineering.
- Improve accuracy and efficiency of machine learning algorithms.
Information data preprocessing is an essential cycle in information science and AI that includes cleaning, changing, and coordinating crude information into a usable configuration. It ensures that ML models can eliminate massive encounters and make careful gauges.
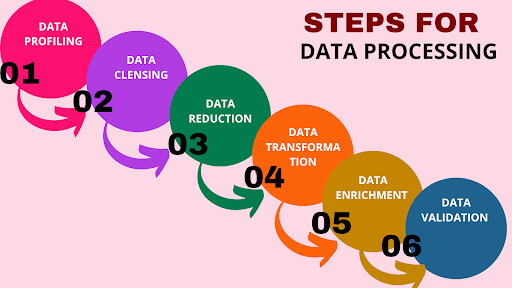
Key Steps in Data Preprocessing
Here are some data preprocessing steps:
1. Data Cleaning
Information cleaning integrates missing attributes, copy records, and mixed-up information segments. A portion of the standard techniques utilized in this step include:
- Eliminating or ascribing missing qualities: Procedures like mean, middle, or mode ascription are broadly utilized.
- Taking care of anomalies: Utilizing Z-score standardization or Interquartile Reach (IQR) strategies.
- Taking out copy passages: Copy records can contort results and should be eliminated.
2. Data Transformation
Data transformation ensures that the dataset is in an optimal format for machine learning algorithms. It includes:
- Normalization and Standardization: Normalization (Min-Max Scaling) scales data between 0 and 1.
- Standardization (Z-score scaling) ensures data follows a normal distribution with a mean of 0 and a standard deviation of 1.
- Encoding categorical data: Label Encoding assigns numerical values to categorical variables.
- One-Hot Encoding creates binary columns for each category.
3. Data Reduction
Tremendous datasets can be computationally expensive to process. Dimensionality decrease procedures help improve the dataset by lessening the number of highlights while holding critical data preprocessing. Normal strategies include:
- Head Part Examination (PCA) – Diminishes dimensionality while saving difference.
- Highlight determination techniques – Kills repetitive or immaterial elements.
4. Data Integration
In real-world scenarios, data is often collected from multiple sources. Data integration merges different datasets to create a unified view. Techniques include:
- Component Objective: Recognizing and uniting duplicate records from different sources.
- Organization Planning: Changing attributes from different datasets.
5. Data Splitting (Training, Validation, Testing Sets)
To assess the exhibition of AI models, data is typically split into three parts:
- Training Set (60-80%) – Used to train the model.
- Validation Set (10-20%) – Used to fine-tune hyperparameters.
- Testing Set (10-20%) – Used to evaluate final model performance.
A well-split dataset prevents overfitting and ensures the model generalizes well to new data.

Data Preprocessing in Machine Learning
Why is data preprocessing in machine learning so important?
AI models are great as the information on which they are prepared. Ineffectively preprocessed information can prompt one-sided models, incorrect expectations, and failures. This is the way data preprocessing further develops AI:
Enhances Model Accuracy
An MIT Sloan Management Review study found that 97% of organizations believe data is essential for their business, but only 24% consider themselves data-driven. This gap is mainly due to poor data quality and inadequate preprocessing.
Reduces Computational Costs
Cleaning and reducing data improves processing speed and model efficiency—a well-preprocessed dataset results in faster training times and optimized model performance.
Mitigates Bias and Overfitting
Data preprocessing guarantees that models don’t overfit loud or insignificant information designs by addressing missing qualities, eliminating exceptions, and normalizing information.

Best Practices for Data Preprocessing
Here are some best practices to follow when preprocessing data:
- Figure out Your Information: Perform exploratory information investigation (EDA) to recognize missing qualities, anomalies, and relationships.
- Handle Missing Qualities Cautiously: Avoid inconsistent substitutions; use space information to settle on attribution strategies.
- Standardize Information Where Fundamental: Normalizing information guarantees decency and forestalls predisposition.
- Mechanize Preprocessing Pipelines: Devices like Scikit-learn, Pandas, and TensorFlow proposition adequate data preprocessing capacities.
- Consistently Screen Information Quality: Keep consistent and identify ongoing oddities utilizing checking instruments.

Conclusion
Data preprocessing is a fundamental stage in the computer-based intelligence lifecycle that ensures data quality, improves model exactness, and smooths computational viability. Data preprocessing systems are key to accomplishing dependable and critical information, from cleaning and change to fuse and component-making decisions.
By performing commonsense information data preprocessing in AI, organizations, and information, researchers can improve model execution, reduce expenses, and gain an advantage.
With 80% of data science work dedicated to data cleaning, mastering data preprocessing is key to building successful machine learning models. Following the best practices outlined above, you can ensure your data is robust, accurate, and ready for AI-driven applications.
How can [x]cube LABS Help?
[x]cube LABS’s teams of product owners and experts have worked with global brands such as Panini, Mann+Hummel, tradeMONSTER, and others to deliver over 950 successful digital products, resulting in the creation of new digital revenue lines and entirely new businesses. With over 30 global product design and development awards, [x]cube LABS has established itself among global enterprises’ top digital transformation partners.
Why work with [x]cube LABS?
- Founder-led engineering teams:
Our co-founders and tech architects are deeply involved in projects and are unafraid to get their hands dirty.
- Deep technical leadership:
Our tech leaders have spent decades solving complex technical problems. Having them on your project is like instantly plugging into thousands of person-hours of real-life experience.
- Stringent induction and training:
We are obsessed with crafting top-quality products. We hire only the best hands-on talent. We train them like Navy Seals to meet our standards of software craftsmanship.
- Next-gen processes and tools:
Eye on the puck. We constantly research and stay up-to-speed with the best technology has to offer.
- DevOps excellence:
Our CI/CD tools ensure strict quality checks to ensure the code in your project is top-notch.
Contact us to discuss your digital innovation plans. Our experts would be happy to schedule a free consultation.