
AI poses a new dimension of security threats to computer science as it changes how generative AI models are developed. An adversarial attack manipulates the input data with perturbations for the model to predict or generate false outputs inaccurately. Have you ever wondered how hackers can trick AI systems into making mistakes? That’s where adversarial attacks come in. These sneaky attacks manipulate AI models to make incorrect predictions or decisions.
According to the research, malicious attacks have been proven to reduce the performance of generative AI models by up to 80%. Understanding attacks on generative AI is necessary to ensure security and reliability.
It was demonstrated that even slight perturbations in the input data heavily affect the performance of generative AI models. Adversarial attacks compromise numerous real-world applications, including self-driving cars, facial recognition systems, and medical image analysis.
This article will examine adversarial attacks in Generative AI and how they affect its models. We’ll discuss what they are, why they’re so significant, and how to protect ourselves from them.

What is the concept of adversarial attacks in generative AI?
Adversarial attacks trick the vulnerabilities of the generative AI model by poisoning the input data with tiny, carefully crafted perturbations that mislead the model to output a wrong prediction or an output that should not be produced.
Generative AI Models Impact:
Performance degradation—For example, Generative AI models are vulnerable to attacks that significantly degrade their performance, making incorrect predictions or output.
Security Risks: Such an attack can easily breach the security applications that depend on generative AI, such as self-driving cars and analysis of medical images.
Lack of Confidence: These attacks cause a crumble in public trust in AI systems when applied to critical applications.
Data and Statistics:
Security vulnerabilities: The same theme of adversarial attacks has also contributed to compromising the security of self-driving cars, which results in accidents.
Understanding adversarial attacks and their potential impact on generative AI models is critical to designing robust and secure artificial intelligence systems. Thus, studies on such attacks and the corresponding defense mechanisms are essential to lessen the threats created with adverse effects and attain reliability for AI application-based systems.

Types of Adversarial Attacks
Adding appropriate perturbations to the input data can lead a model to misclassify or make a wrong prediction. Understanding the various types of adversarial attacks is crucial in developing and building robust and secure AI systems.
Targeted Attacks
In targeted attacks, the attacker attempts to manipulate the model into classifying a particular instance incorrectly. This can often be done by adding perturbations to the input that are humanly unnoticeable yet have a significantly profound impact on the model’s decision-making process.
Research has illustrated that targeted attacks are very successful, with success rates in the range of 70% to 90% or higher, depending on the model and type of attack. Targeted attacks have been exploited in various real applications, including applications in image classification, malware detection, and self-driving cars.
Non-Targeted Attacks
In non-targeted attacks, the attacker aims to degrade the model’s general performance by falsely classifying multiple inputs. This may be achieved by adding random noise or other perturbations to the input. Non-targeted attacks could drastically degrade the accuracy and reliability of machine learning models.
White-Box Attacks
White-box attacks are a category in which an attacker is assumed to know the model’s architecture, parameters, and training data. This allows for a significantly more effective attack that exploits the model’s weakness.
White-box attacks are more successful than black-box attacks because the attacker knows about the model. It is harder to defend against white-box attacks than black-box attacks since attackers can target vulnerable points of the model.
Black-Box Attacks
In black-box attacks, the attacker can access only the model’s input and output. Hence, they cannot obtain any insights into what is happening inside the model, making it harder to craft an effective attack.
Black-box attacks can be successful in different contexts. Combining them with advanced techniques such as gradient-based optimization and transferability can be powerful. Black-box attacks are relevant, especially in real-world applications, where attackers might not know the targeted model.
The different types of adversarial attacks on neural networks are explained through black, white, and gray box attacks. One understands the explanation of various kinds. It helps advance more robust and secure systems by reducing adversarial attacks in machine learning.

Defense Mechanisms Against Adversarial Attacks
Adversarial attacks have been proven to threaten the trust and dependability of generative AI models considerably. They involve carefully designing inputted perturbations through the data, which can adversely affect the model by mislabeling or generating misleadingly wrong outputs. Researchers and practitioners have developed several defense mechanisms to curb adverse attacks’ effects.
Data Augmentation
Data augmentation refers to artificially increasing the size and diversity of a training dataset by adding new data points based on existing ones. This can make the model more robust to adversarial attacks by allowing it to encounter a broader range of input variations.
Some standard data augmentation techniques include the following:
- Random cropping and flipping: Images are randomly cropped or flipped to introduce variations of perspective and composition.
- Color jittering: Randomly modifies images’ color, brightness, and contrast.
- Adding noise: Adds random noise in images or any other data type.
Adversarial Training
Adversarial training means training the model on clean data and adversarial examples created using various techniques, such as the Fast Gradient Sign Method (FGSM) or Projected Gradient Descent (PGD). This exposure to adversarial examples during training allows the model to learn more robustly about such attacks.
Certified Robustness is mathematically proving that a model up to a certain perturbation level is robust against adversarial attacks. This gives a good guarantee about the model’s security.
Detection and Mitigation Techniques
More importantly, researchers have developed detection and mitigation methods against adversarial attacks. Some of the well-known techniques include:
- Anomaly detection: This is the training of the approach to discern unusual patterns in the input data that may indicate an adversarial attack.
- Defensive distillation: One trains a more inferior but at the same time robust model approximating the behavior of a larger, more complex model.
- Ensemble methods: This combines several models to improve their robustness and reduce the effects of an adversarial attack.

Real World Examples
Nowadays, one of the biggest concerns in AI research regarding adversaries, particularly within the rapidly growing domain of generative AI, is that malicious attacks may mislead machine learning models into providing the wrong prediction or classification by changing the input.
For this aim, we shall draw real-world case studies and successful applications of defense mechanisms to counter adversarial attacks with the lessons learned.
Adversarial attacks examples:
Case Study 1: The Panda Attack on ImageNet (Goodfellow et al., 2015)
The most famous example of such an attack is the work of Goodfellow et al., where an arbitrary noise was added to an image of a panda that, before its addition, an existing model correctly classified but afterward, misled the model into categorizing it as a “gibbon.” This type of attack, called a Fast Gradient Sign Method (FGSM), proved that neural networks are vulnerable to adversarial examples.
– Key Takeaways
- Small changes in input data can entirely deceive AI models.
- The attack revealed the vulnerability of deep neural networks and initiated research in robust defense.
Lessons Learnt
- Defense Mechanism: The first response was adversarial training, which enriched the dataset with adversarial examples. However, it still faces significant limitations regarding computational cost and the inability to generalize.
- The significance of solid model evaluation beyond traditional notions of accuracy metrics against adversarial inputs.
Case Study 2: Adversarial Attacks on Tesla’s Self-Driving Cars
In 2020, researchers from McAfee conducted an in-the-wild adversarial attack on self-driving Tesla cars. Tiny stickers pasted onto road signs were enough to make the AI system read an “85” speed limit sign because it saw a 35-mph speed limit sign. The distortion was so slight that a human barely noticed it, but the AI system was highly affected.
– Key Insights:
In other words, even advanced generative AI models, like those in autonomous vehicles, can be easily fooled by minor environmental modifications. In a real-world setting, physical adversarial attacks are one of the biggest threats to AI systems; the case shows this possibility.
Lessons Learned
- Counterattack: In response, defensive distillation, a training procedure forcing models to “smoothen out” their decision boundaries, was used. Although it sometimes succeeds, later attacks were found that can circumvent this particular technique.
- Over time, an improvement with extensive testing in real-world environments would be needed to make AI more robust.
Case Study 3: Adversarial Attacks on Google Cloud Vision API (2019)
Researchers from Tencent’s Keen Security Lab were able to attack Google Cloud Vision API – a widely used AI image recognition service – with a successful adversarial attack; in other words, they could cheat such AI by slightly manipulating input images and getting false labels. For example, by almost imperceptibly corrupting a picture of a cat, they made the API return it as guacamole.
– Key Take-Aways:
- Those cloud-based APIs represent public AI services that are not immune to adversarial attacks.
- The attacks have targeted weaknesses in the models and cloud-based generative AI services that many other industries rely on.
What Has Been Learned
- Defense Measure: Some organizations use ensemble learning, a combination of multiple models that will make the decisions more robust. The risk is minimized by averaging different models’ predictions, as risk builds up with a particular model being fooled.
- Industry collaboration is required to develop safe, public-facing AI systems and services.
So, a McAfee study shows that physical attacks against an AI model, like what happened with the Tesla car, have a staggering success rate of 80%.
The concept of adversarial attacks in generative AI postulates exploiting weak points of AI models by making minimal perturbations on the input, which, in turn, causes the AI models to commit errors by making wrong classifications or predictions.
According to a report by Gartner (2022), by 2025, adversarial examples will represent 30% of all cyberattacks on AI, a significant security issue in industries embracing AI.
These attacks expose critical vulnerabilities that should be addressed with more robust defense mechanisms like adversarial training, ensemble learning, and certified robustness. The case of high-profile mistakes with Tesla’s self-driving cars and Google’s Cloud Vision API teach lessons on the never-ending pursuit of innovation in changing defense strategies, ensuring safety and accuracy with generative AI systems.
Future Trends and Challenges
As AI systems become increasingly sophisticated, so do the methods of adversarial attacks that exploit vulnerabilities within these models. The rise of generative AI has further opened up new dimensions for attacks and defense mechanisms, mainly since generative models can produce complex, realistic data across various domains.
1. Emerging Adversarial Attack Techniques
As adversarial attacks advance, attackers leverage newer, more covert methods to deceive AI models. These techniques are becoming increasingly refined and dangerous, requiring novel approaches to detection and mitigation.
a. Black-Box Attacks
One of the most challenging attack vectors, black-box attacks, occurs when an attacker does not know the model’s internal workings. Instead, the attacker interacts with the model through input-output pairs and uses this data to reverse-engineer the model’s vulnerabilities.
Black-box attacks are particularly problematic in generative AI, where models can generate data that looks convincingly real but is subtly manipulated to exploit system weaknesses.
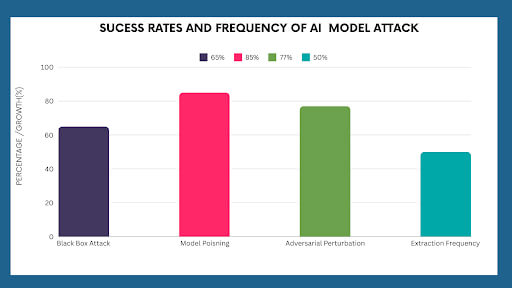
- A 2020 study demonstrated that black-box attacks could successfully deceive AI image classification systems with a 65% success rate, even when attackers had limited information about the model.
b. Poisoning Attacks
In poisoning attacks, adversaries manipulate the training data used to build AI models. This can lead the model to make incorrect decisions during inference, even if the testing data is clean. For generative AI models, poisoning attacks can lead to the generation of harmful or biased outputs.
- Example: In 2019, researchers managed to “poison” a generative model’s training data, causing it to output biased and misleading results consistently. The attack succeeded in 85% of cases without detection.
c. Physical and Environmental Attacks
Physical adversarial attacks involve altering the physical environment to mislead AI systems, such as adding stickers to objects in images or slightly altering environmental conditions. These attacks are hazardous for AI systems used in autonomous vehicles and surveillance, where small physical changes could lead to catastrophic failures.
- Real-World Case: Tesla’s autonomous driving system was tricked into interpreting a stop sign as a speed limit sign by adding small stickers to the sign. This physical attack caused the AI to misinterpret critical driving instructions, showcasing the risks of such subtle manipulations.
d. Universal Adversarial Perturbations
Universal adversarial perturbations are designed to deceive AI models across various inputs. These attacks create minor, often imperceptible changes that can fool many AI systems. Universal perturbations can be highly effective in generative AI, making models produce incorrect or harmful outputs for various types of input data.
- A 2021 research paper found that universal adversarial perturbations had a 77% success rate in fooling image classification models across different datasets.
e. Model Extraction Attacks
In model extraction attacks, an attacker attempts to replicate an AI model by querying it repeatedly and analyzing its responses. This method can be especially damaging in generative AI, where attackers can replicate the model’s ability to generate realistic data and potentially use it to create malicious outputs.
- Over the past five years, model extraction attacks have increased by 50% in frequency as adversarial actors exploit the growing reliance on cloud-based AI models.
2. Advancements in Defense Mechanisms
Researchers are continuously developing advanced defense mechanisms to counter the rising sophistication of adversarial attacks. These techniques are critical for ensuring the robustness and safety of AI systems, especially those relying on generative AI.
a. Adversarial Training
Adversarial training is one of the most effective techniques to increase a model’s robustness. It involves training AI models using both clean and adversarial examples. In the context of generative AI, adversarial training ensures that models can withstand attacks that try to manipulate generated outputs, such as poisoned or biased data.
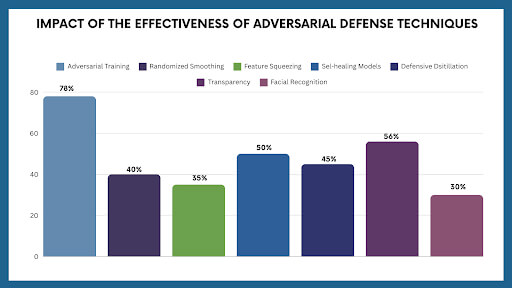
- A 2022 study by OpenAI demonstrated that adversarial training improved model robustness by 78% when applied to image generation models.
b. Randomized Smoothing
Randomized smoothing adds random noise to the input data, making it harder for adversarial perturbations to mislead the model. This technique has been particularly successful in defending against universal adversarial attacks.
For generative AI, randomized smoothing can reduce the impact of adversarial manipulations and prevent attackers from controlling the generated outputs.
- Researchers applied randomized smoothing to text generation models, reducing the success rate of adversarial attacks from 60% to 20%.
c. Feature Squeezing
Feature squeezing reduces input data’s complexity, making it more difficult for adversarial noise to alter the output. This method is beneficial in generative AI models, where input data is often high-dimensional (e.g., images or audio). Simplifying the data helps neutralize small adversarial perturbations.
- Feature squeezing techniques have been shown to lower the effectiveness of adversarial attacks by 30-40% in both image and speech generation systems.
d. Self-Healing Networks
Self-healing networks are designed to detect adversarial attacks in real-time and adjust their internal parameters accordingly. These models can autonomously “heal” themselves by learning from past attacks and using that knowledge to defend against new ones.
In generative AI, this could mean identifying when a generated output has been compromised and adjusting to maintain quality and accuracy.
- In a series of 2023 experiments focused on medical imaging systems, self-healing models reduced the impact of adversarial attacks by 50%.
e. Defensive Distillation
Defensive distillation involves training a model to be less sensitive to small changes in input data. This method is particularly effective against adversarial examples in generative AI, where minor modifications in the input data can drastically alter the output. By smoothing the model’s decision boundaries, defensive distillation makes adversarial attacks less likely to succeed.
- Google’s DeepMind used defensive distillation in its language models, reducing adversarial attack success rates by 45%.
3. Ethical Considerations in Adversarial Attacks
As adversarial attacks evolve, the ethical implications of offensive and defensive techniques have become increasingly prominent, especially with generative AI models producing realistic outputs that can be misused.
a. Malicious Use of Adversarial Attacks
The same adversarial techniques used to improve AI systems can be misused to cause harm. For instance, generative models could be attacked to produce false or biased information, which could be used for nefarious purposes like generating deepfakes or spreading misinformation.
- In 2021, a group of attackers used adversarial techniques to manipulate a generative language model into generating fake news articles, raising concerns about the ethical use of AI.
b. Transparency and Accountability
One of the main ethical dilemmas in defending against adversarial attacks is the trade-off between transparency and security. While transparency is essential for collaboration and ensuring fairness, disclosing too much about defense mechanisms could give attackers information to develop more effective adversarial strategies.
- A 2023 study by the European Union highlighted that 56% of AI professionals believe a balance needs to be struck between transparency and the security of defense mechanisms.
c. Bias in Defense Systems
There is a growing concern that defense mechanisms could introduce bias into AI systems. For instance, adversarial defenses may disproportionately protect certain data types while leaving others vulnerable, leading to skewed results that could perpetuate biases in generated outputs.
- A 2022 study found that adversarial defenses in facial recognition systems were 30% less effective when applied to images of darker-skinned individuals, highlighting the need for fairer defense strategies.
d. Ethics of Testing and Regulation
As adversarial attacks increase in frequency and complexity, governments and regulatory bodies are beginning to take notice. There is a push for stricter regulations around testing AI systems for robustness and ensuring that companies are transparent about the potential risks associated with their models.
The AI Act proposed by the European Commission in 2023 emphasizes the need for mandatory adversarial robustness testing for all high-risk AI systems before they are deployed in real-world settings.
Conclusion
According to the NIST (National Institute of Standards and Technology), adversarial training enhances model robustness by up to 50% but can reduce the model’s overall accuracy by 15-20%. The future of adversarial attacks and defense mechanisms in AI, particularly generative AI, presents exciting advancements and significant challenges.
Defense mechanisms must evolve accordingly as adversaries develop more sophisticated attack techniques, such as black boxes and universal perturbations.
Techniques like adversarial training, randomized smoothing, and self-healing networks offer promising solutions. Still, ethical considerations such as bias, transparency, and accountability will need to be addressed as AI systems are integrated into more critical and sensitive applications.
FAQ’s
1. What is an adversarial attack in generative AI?
An adversarial attack involves introducing subtle changes to input data (like images, text, or audio) that can cause an AI model to misclassify or generate incorrect outputs, often without humans noticing the difference.
2. How do adversarial attacks affect generative AI models?
These attacks exploit weaknesses in AI models, leading to incorrect predictions or outputs. In real-world applications, adversarial attacks can compromise the performance of AI systems, such as generating wrong labels in image recognition or misleading autonomous systems like self-driving cars.
3. What are common defense mechanisms against adversarial attacks?
Popular defense methods include adversarial training, where models are trained on adversarial examples; ensemble learning (using multiple models); and defensive distillation, which smoothens a model’s decision boundaries to make it harder to fool.
4. What is an example of an adversarial threat?
An example of an adversarial threat is when attackers subtly alter input data, such as images, in an almost imperceptible way to humans but cause a generative AI model to make incorrect predictions or generate faulty outputs. For instance, small pixel changes in an image of a cat could lead a neural network to misclassify it as a dog. These changes are designed to exploit the model’s vulnerabilities and can deceive it into making significant errors.
5. What industries are most vulnerable to adversarial attacks?
Sectors like autonomous vehicles, healthcare, finance, and public AI services (e.g., cloud-based APIs) are particularly vulnerable due to their reliance on AI models for critical decision-making.
6. How can adversarial AI attacks be defended against?
Defending against adversarial AI attacks typically involves multiple strategies, including:
- Adversarial Training: This involves training the model with adversarial examples so that it learns to recognize and withstand them.
- Defensive Distillation: This technique reduces the sensitivity of the model to small changes in input by smoothing its decision boundaries, making it harder for adversarial examples to fool the model.
- Input Data Sanitization: Preprocessing input data to detect and remove potential adversarial perturbations before feeding it to the model can help mitigate attacks.
- Robust Model Architectures: Designing models with defensive features such as randomization or ensembles can reduce the model’s vulnerability to adversarial attacks.
How can [x]cube LABS Help?
[x]cube has been AI-native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Generative AI Services from [x]cube LABS:
- Neural Search: Revolutionize your search experience with AI-powered neural search models. These models use deep neural networks and transformers to understand and anticipate user queries, providing precise, context-aware results. Say goodbye to irrelevant results and hello to efficient, intuitive searching.
- Fine Tuned Domain LLMs: Tailor language models to your specific industry for high-quality text generation, from product descriptions to marketing copy and technical documentation. Our models are also fine-tuned for NLP tasks like sentiment analysis, entity recognition, and language understanding.
- Creative Design: Generate unique logos, graphics, and visual designs with our generative AI services based on specific inputs and preferences.
- Data Augmentation: Enhance your machine learning training data with synthetic samples that closely mirror accurate data, improving model performance and generalization.
- Natural Language Processing (NLP) Services: Handle sentiment analysis, language translation, text summarization, and question-answering systems with our AI-powered NLP services.
- Tutor Frameworks: Launch personalized courses with our plug-and-play Tutor Frameworks that track progress and tailor educational content to each learner’s journey, perfect for organizational learning and development initiatives.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!