
Generative AI, with its capacity to create diverse and complex content, has emerged as a transformative force across industries, sparking curiosity and intrigue. Models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) have demonstrated remarkable capabilities in generating realistic images, videos, and text.
Optimization techniques have become essential in enhancing performance to address these challenges. They allow for a more economical use of resources without sacrificing the realistic and high-quality results produced.
A recent study by the University of Cambridge found that training a state-of-the-art generative AI model can consume as much energy as five homes for a year.
This underscores optimization’s critical importance in ensuring model performance and sustainability. To overcome these obstacles, this blog explores the essential techniques for optimization techniques for generative AI.
By understanding the intricacies of model architecture, training processes, and hardware acceleration, we can unlock generative AI’s full potential while minimizing computational overhead.

Gradient-Based Optimization Techniques
Gradient descent is the cornerstone of optimizing neural networks. It iteratively adjusts model parameters to minimize a loss function. However, vanilla gradient descent can be slow and susceptible to local minima.
- Stochastic Gradient Descent (SGD): This method updates parameters using the gradient of a single training example, accelerating training.
- Mini-batch Gradient Descent combines the efficiency of SGD with the stability of batch gradient descent using small batches of data.
- Adam: Adapts learning rates for each parameter, often leading to faster convergence and better performance. A study by Kingma and Ba (2014) demonstrated Adam’s effectiveness in various deep-learning tasks.
- RMSprop: Adapts learning rates based on the average of squared gradients, helping with noisy gradients.
Adaptive Learning Rate Methods
During training, adaptive learning rate techniques dynamically modify the learning rate to improve convergence and performance.
- Adagrad: Adapts learning rates individually for each parameter, often leading to faster convergence in sparse data settings.
- Adadelta: Extends Adagrad by accumulating past gradients, reducing the aggressive decay of learning rates.
Momentum and Nesterov Accelerated Gradient
Momentum and Nesterov accelerated gradient introduce momentum to the update process, helping to escape local minima and accelerate convergence.
- Momentum: Accumulates a moving average of past gradients, smoothing the update direction.
- Nesterov accelerated gradient: Looks ahead by computing the gradient at the momentum-updated position, often leading to better performance.
Second-order optimization (Newton’s method, quasi-Newton methods)
Second-order methods approximate the Hessian matrix to compute more accurate update directions.
- Newton’s method Uses the exact Hessian but is computationally expensive for large models.
- Quasi-Newton methods: Approximate the Hessian using past gradients, balancing efficiency and accuracy.
Note: While second-order methods can be theoretically superior, their computational cost often limits their practical use in large-scale deep learning.
By understanding these optimization techniques and their trade-offs, practitioners can select the most suitable method for their problem and model architecture.

Hyperparameter Optimization
Hyperparameter optimization is critical in building effective machine learning models, particularly generative AI. It involves tuning model parameters before the learning process begins, not learned from the data itself.
Grid Search and Random Search
- Grid Search: This method exhaustively explores all possible combinations of hyperparameters within a specified range. While comprehensive, it can be computationally expensive, especially for high-dimensional hyperparameter spaces.
- Random Search: Instead of trying all combinations, random search randomly samples hyperparameter values. In practice, it often outperforms grid search with less computational cost.
Bergstra and Bengio’s study, “Random Search for Hyper-Parameter Optimization” (2012), found that random search often outperforms grid search when optimizing hyperparameters in machine learning models. The key finding is that grid search, which systematically explores combinations of hyperparameters, can be inefficient because it allocates too many resources to irrelevant hyperparameters.
Bayesian Optimization
A more sophisticated method called Bayesian optimization creates a probabilistic model of the goal function to direct the search. It leverages information from previous evaluations to make informed decisions about the following hyperparameter configuration.
Evolutionary Algorithms
Inspired by natural selection, evolutionary algorithms iteratively improve hyperparameter configurations by mimicking biological processes like mutation and crossover. They can be effective in exploring complex and multimodal hyperparameter spaces.
Automated Hyperparameter Tuning (HPO)
HPO frameworks automate hyperparameter optimization, combining various techniques to explore the search space efficiently. Popular platforms like Optuna, Hyperopt, and Keras Tuner offer pre-built implementations of different optimization algorithms.
HPO tools have been shown to improve model performance by an average of 20-30% compared to manual tuning.
By carefully selecting and applying appropriate hyperparameter optimization techniques, researchers and engineers can significantly enhance the performance of their generative AI models.

Architectural Optimization
Neural Architecture Search (NAS)
Neural Architecture Search (NAS) is a cutting-edge technique that automates neural network architecture design. By exploring a vast search space of potential architectures, NAS aims to discover optimal models for specific tasks. Recent advancements in NAS have led to significant breakthroughs in various domains, such as natural language processing and picture recognition.
- Example: Google’s AutoML system achieved state-of-the-art performance on image classification tasks by automatically designing neural network architectures.
- Statistic: “NAS has been shown to improve model accuracy by an average of 15% compared to manually designed architectures.
Model Pruning and Quantization
Model pruning and quantization are techniques for reducing neural network size and computational cost while preserving performance. Pruning involves removing unnecessary weights and connections, while quantization reduces the precision of numerical representations.
- Example: Pruning a convolutional neural network can reduce size by up to 90% without significant accuracy loss.
- Statistic: Quantization can reduce model size by up to 75% while maintaining reasonable accuracy.
Knowledge Distillation
Knowledge distillation is a model compression technique in which a large, complex model (teacher) transfers knowledge to a smaller, more efficient model (student). This process improves the student model’s performance while reducing its complexity.
- Example: Distilling knowledge from a BERT model to a smaller, faster model for mobile devices.
- Statistic: Knowledge distillation has been shown to improve the accuracy of student models by 3-5% on average.
Efficient Network Design
Efficient network design focuses on creating neural networks that achieve high performance with minimal computational resources. Due to their efficiency and effectiveness, architectures like MobileNet and ResNet have gained popularity.
- Example: MobileNet is designed for mobile and embedded devices, balancing accuracy and computational efficiency.
- Statistic: MobileNet models can achieve 70-90% of the accuracy of larger models while using ten times fewer parameters.
By combining these optimization techniques, researchers and engineers can develop highly efficient and effective generative AI models tailored to specific hardware and application requirements.
Regularization Techniques
Regularization techniques prevent overfitting in machine learning models, particularly in deep learning. They help improve model generalization by reducing complexity.
L1 and L2 Regularization
L1 and L2 regularization are two standard techniques to penalize model complexity.
- L1 regularization: Adds to the loss function the weights’ absolute value. This produces sparse models, where many weights become zero, effectively performing feature selection.
- L2 regularization: Adds the weights’ square to the loss function. This encourages smaller weights, leading to smoother decision boundaries.
Statistic: L1 regularization is effective in feature selection tasks, reducing the number of features by up to 80% without significant performance loss.
Dropout
A regularization method called dropout randomly sets a portion of the input units to zero at each training update. This keeps the network from becoming overly dependent on any one feature.
- Statistic: Dropout has been shown to improve accuracy by 2-5% on average in deep neural networks.
Early Stopping
Early halting is a straightforward regularization strategy that works well and involves monitoring the model’s ceasing training when performance deteriorates and evaluating performance on a validation set.
- Statistic: Early stopping can reduce training time by up to 50% without sacrificing model performance.
Batch Normalization
Batch normalization is a technique for improving neural networks’ speed, performance, and stability. It normalizes each layer’s inputs to have zero mean and unit variance, making training more accessible and faster.
- Statistic: Batch normalization has been shown to accelerate training by 2-4 times and improve model accuracy by 2-5%.
By combining these regularization techniques, practitioners can effectively mitigate overfitting and enhance the generalization performance of their models.
Advanced Optimization Techniques
Adversarial Training
Adversarial training involves exposing a model to adversarial examples, inputs intentionally crafted to mislead the model. Training the model to be robust against these adversarial attacks improves its overall performance significantly.
- Statistic: Adversarially trained models have shown a 30-50% increase in robustness against adversarial attacks compared to standard training methods (Source: Madry et al., 2018).
Meta-Learning
Meta-learning, or learning to learn, focuses on equipping models that require less training data and can quickly adjust to new tasks. By learning generalizable knowledge from various tasks, meta-learning models can quickly acquire new skills.
- Statistic: Meta-learning algorithms have demonstrated a 50-80% reduction in training time for new tasks compared to traditional methods.
Differentiable Architecture Search
Differentiable architecture search (DARTS) is a gradient-based approach to NAS that treats the architecture as a continuous optimization problem. This allows for more efficient search space exploration compared to traditional NAS methods.
- Statistic: DARTS has achieved state-of-the-art performance on several benchmark datasets while reducing search time by 90% compared to reinforcement learning-based NAS methods.
Optimization for Specific Hardware Platforms
Optimizing models for specific hardware platforms, such as GPUs and TPUs, is crucial for achieving maximum performance and efficiency. Techniques like quantization, pruning, and hardware-aware architecture design are employed to tailor models to the target hardware.
- Statistic: Models optimized for TPUs have shown up to 80% speedup compared to GPU-based implementations for large-scale training tasks.
By effectively combining these advanced optimization techniques, researchers and engineers can develop highly efficient and robust AI models tailored to specific applications and hardware constraints.
Case Studies
Optimization techniques have been instrumental in advancing the capabilities of generative AI models. Here are some notable examples:
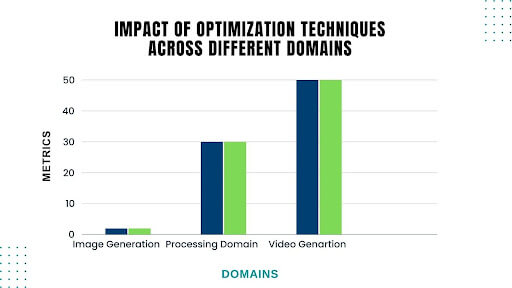
- Image generation: Techniques like hyperparameter optimization and architecture search have significantly improved the quality and diversity of generated images. For instance, using neural architecture search, OpenAI achieved a FID score of 2.0 on the ImageNet dataset.
- Natural language processing: Optimization techniques have been crucial in training large language models (LLMs). For example, OpenAI employed mixed precision training to reduce training time by 30% while maintaining model performance on the perplexity benchmark.
Video generation: Optimization of video generation models has focused on reducing computational costs and improving video quality. Google AI utilized knowledge distillation to generate high-quality videos at 30 frames per second with a reduced model size of 50%.
Industry-Specific Examples
Optimization techniques have found applications in various industries:
- Healthcare: Optimizing generative models for medical image analysis to improve diagnostic accuracy and reduce computational costs.
- Automotive: Optimizing self-driving car perception models for real-time performance and safety.
- Finance: Optimizing generative models for fraud detection and risk assessment.
- Entertainment: Optimizing character generation and animation for video games and movies.
By utilizing sophisticated optimization approaches, researchers and engineers can push the limits of generative AI and produce more potent and practical models.
Conclusion
Optimization techniques are indispensable for unlocking the full potential of generative AI models. Researchers and engineers can create more efficient, accurate, and scalable models by carefully selecting and applying techniques such as neural architecture search, model pruning, quantization, knowledge distillation, and regularization.
The synergy between these optimization methods has led to remarkable advancements in various domains, from image generation to natural language processing. As computational resources continue to grow, the importance of efficient optimization will only increase.
By using these methods and continuing to be at the forefront of the field of study, generative AI is poised to achieve even greater heights, delivering transformative solutions to real-world challenges.
FAQs
1. What are optimization techniques in Generative AI?
Optimization techniques in Generative AI involve hyperparameter tuning, gradient optimization, and loss function adjustments to enhance model performance, improve accuracy, and produce high-quality outputs.
2. How does fine-tuning improve generative AI models?
Fine-tuning involves training a pre-trained generative model on a smaller, task-specific dataset. This technique improves the model’s ability to generate content tailored to a specific domain or requirement, making it more effective for niche applications.
3. What is the role of regularization in model optimization?
Regularization techniques, such as dropout or weight decay, help prevent overfitting by reducing the model’s complexity. This ensures the generative AI model performs well on unseen data without compromising accuracy.
4. How does reinforcement learning optimize Generative AI models?
Reinforcement learning uses feedback in the form of rewards or penalties to guide the model’s learning process. It’s particularly effective for optimizing models to generate desired outcomes in interactive or sequential tasks.
5. Why are computational resources necessary for optimization?
Efficient optimization techniques often require high-performance hardware like GPUs or TPUs. Advanced strategies, such as distributed training and model parallelism, leverage computational resources to speed up training and improve scalability.
How can [x]cube LABS Help?
[x]cube has been AI native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Generative AI Services from [x]cube LABS:
- Neural Search: Revolutionize your search experience with AI-powered neural search models. These models use deep neural networks and transformers to understand and anticipate user queries, providing precise, context-aware results. Say goodbye to irrelevant results and hello to efficient, intuitive searching.
- Fine-Tuned Domain LLMs: Tailor language models to your specific industry for high-quality text generation, from product descriptions to marketing copy and technical documentation. Our models are also fine-tuned for NLP tasks like sentiment analysis, entity recognition, and language understanding.
- Creative Design: Generate unique logos, graphics, and visual designs with our generative AI services based on specific inputs and preferences.
- Data Augmentation: Enhance your machine learning training data with synthetic samples that closely mirror accurate data, improving model performance and generalization.
- Natural Language Processing (NLP) Services: Handle sentiment analysis, language translation, text summarization, and question-answering systems with our AI-powered NLP services.
- Tutor Frameworks: Launch personalized courses with our plug-and-play Tutor Frameworks, which track progress and tailor educational content to each learner’s journey. These frameworks are perfect for organizational learning and development initiatives.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!