 1-800-805-5783
1-800-805-5783  GET A QUOTE
GET A QUOTE
![Blog-[x]cube LABS](https://d6fiz9tmzg8gn.cloudfront.net/wp-content/uploads/2016/06/blog_banner.jpg)


By [x]cube LABS
Published: Sep 13 2024

Data augmentation, a significant and potent technique for artificially expanding a training dataset’s size and variety, has enhanced the accuracy of generative AI models by 5-10%. This promising result from a recent Google AI study underscores the 5-10% role of data augmentation in the future of AI.
Data augmentation, a process of applying various transformations to existing data, is crucial in enhancing the generalization capabilities of machine learning models, including AI-generated models.
Data augmentation is paramount in training generative AI models. These models rely on high-quality data to grasp complex patterns and produce realistic outputs.
However, obtaining sufficient and diverse data can be challenging, especially in domains with limited resources or sensitive information. Data augmentation provides a means to address these limitations by expanding the training dataset without collecting additional raw data.
Limited and biased datasets can significantly hinder the performance of AI-generated models. If a dataset is too small or lacks diversity, the model may struggle to learn the underlying distribution of the data and may generate biased or unrealistic outputs. Data augmentation can help to mitigate these issues by introducing additional variation and reducing the risk of overfitting.
We aim to empower you by discussing standard techniques, case studies, advanced strategies, and best practices for effective data augmentation. Understanding and using these strategies can significantly enhance the performance and robustness of your generative AI models, giving you the confidence to tackle complex AI challenges.

Statistics:

A valuable method for expanding the variety and breadth of training datasets is data augmentation, improving the generalization and robustness of AI models. By artificially altering existing data, data augmentation helps models learn more invariant features and reduce overfitting.
A study by Harvard Natural Language Processing Group demonstrated that text augmentation techniques can improve the performance of natural language processing tasks by 5-10%.
Audio augmentation has been shown to improve the accuracy of speech recognition models by 10-20%, especially in noisy environments.
Adversarial training has improved the robustness of AI models against adversarial attacks, reducing their vulnerability to malicious manipulation.
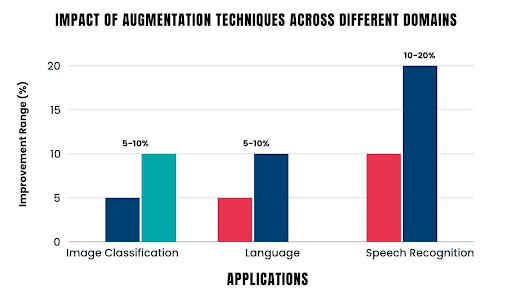
Image Generation:
Natural Language Processing:
Healthcare:
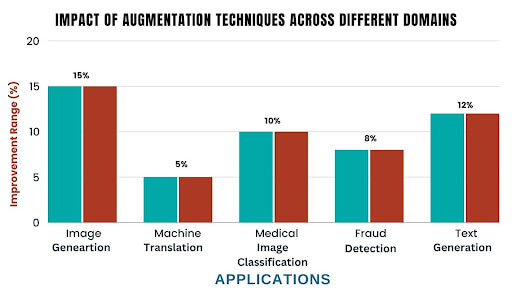
Case Studies Showcasing the Benefits of Data Augmentation
Industry-Specific Applications
Generative Adversarial Networks for Synthetic Data Generation
GANs are powerful tools for creating synthetic data that can augment training datasets. By pitting a generator against a discriminator, the highly realistic data that GANs can produce can enhance the resilience and generalization of AI models.
A study by NVIDIA demonstrated that using GANs to generate synthetic images can improve the accuracy of image classification models by 5-10%. This is because GANs can develop highly realistic images that augment the training dataset, helping models learn more robust and generalizable features.
AutoAugment is a technique that automatically discovers the optimal data augmentation policies for a given task. By searching through a vast space of possible augmentation operations, AutoAugment can find combinations that maximize model performance.
AutoAugment has been shown to improve the accuracy of image classification models by 3-5% compared to manually designed augmentation policies. Demonstrates the effectiveness of automated data augmentation techniques in optimizing model performance and reducing the need for manual experimentation.
The “learning to learn,” or meta-learning, can be used with data augmentation to develop models that can adapt their augmentation strategies to different tasks or data distributions. Data augmentation in deep learning, which is to learn from various functions of meta-learning, can help models generalize better and become more robust to different data challenges.
A study by Google AI demonstrated that meta-learning can be used to automatically discover effective data augmentation policies for various computer vision tasks.
By leveraging advanced techniques like GANs, AutoAugment, and meta-learning, researchers and practitioners can create even more diverse and influential training datasets, further enhancing the performance and robustness of generative AI models.

The choice of data augmentation techniques depends on the dataset’s specific characteristics and the AI model’s desired properties. Consider the following factors:
While data augmentation can improve model performance, excessive augmentation can introduce noise and hinder generalization. Finding the right balance between data augmentation and model complexity is essential.
A study by MIT found that biased data augmentation techniques can lead to biased models, reinforcing existing societal prejudices. Considering these things, you can successfully leverage data augmentation to train robust and ethical generative AI models.

The practical data augmentation method can significantly enhance the performance and robustness of generative AI models. By increasing the diversity and size of training datasets, data augmentation helps models learn more invariant features, reduce overfitting, and improve generalization.
Practitioners play a pivotal role in the effective use of data augmentation. By judiciously selecting suitable augmentation techniques, balancing their intensity with model complexity, and considering ethical implications, they can harness the power of data augmentation to train state-of-the-art generative AI models.
As the field of generative AI continues to evolve, data augmentation will remain a crucial component for developing cutting-edge applications that can benefit society in countless ways.
1) What is data augmentation?
Data augmentation is a technique for increasing the size and diversity of a training dataset by artificially creating new data points from existing ones.
2) What are the standard data augmentation techniques for generative AI?
Standard techniques include random cropping, flipping, rotation, color jittering, and adding noise.
3) How does data augmentation help prevent overfitting in generative AI models?
Data augmentation can reduce the risk of the model memorizing the training data instead of learning general patterns by exposing it to a broader variety of data.
4) How can data augmentation be customized for specific generative AI tasks?
Data augmentation techniques can be tailored to the specific characteristics of the data and the task at hand.
For example, random cropping and rotation techniques may be more appropriate for image-based tasks. In contrast, word replacement and synonym substitution may be more effective for text-based tasks.
5) What are some advanced data augmentation techniques for generative AI?
Advanced techniques include GAN-based data augmentation, adversarial training, and self-supervised learning.
[x]cube has been AI-native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!




